O árboles y humitos: Este post es el par de mi lado del post Python más rápido que Java que escribió Humitos hace algunos días.
Arranquemos desde el principio... una mañana en la que entra Humitos al canal IRC de Python Argentina (#pyar en irc.freenode.net), y plantea el problema de cual es la mejor estructura de datos para armar un autocompletador de palabras. Esto es, a partir de un diccionario de palabras, que estructura las guarda mejor para que cuando uno ponga joye, el sistema sugiera joyel, joyelero, joyero y joyer.
Yo pensé en un árbol con una letra por nodo. Al toque, le sugirieron que usase un árbol Trie. Yo, que como no soy informático no conozco muchos nombres, fui a revisar qué era un árbol Trie.
La cuestión es que un árbol Trie era lo que yo pensaba que era: un árbol con una letra por nodo. Por ejemplo, para las palabras que usé antes:
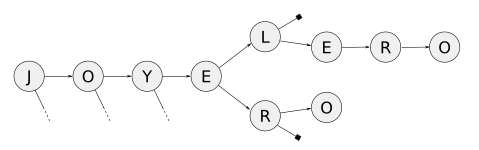
Perfecto. Humitos tenía la tortura de tener que hacer esto en Java para la facultad, así que luego de llorar un rato puso manos a la obra. Iba como "reportando" en el canal de PyAr, e hizo un par de preguntas. Yo, viendo que era difícil discutir el tema desde lo abstracto, me tomé un rato e hice una implementación en Python y se la pasé.
Salió bastante derechita. Básicamente hice una clase Nodo que mantenía la letra, los ramas hijas, y un flag para indicar que hasta ahí llegaba la palabra. Parecía andar, tanto que Humitos termino implementando casi lo mismo en Java.
Al otro día, sin embargo, Humitos me dió dos malas noticias. La primera, era que el sistema este consumía mucha memoria... para el diccionario de más de 80 mil palabras, ¡¡el árbol armado ocupaba 180 MB!!. Como efecto secundario, tardaba mucho en armar la estructura en memoria (como 7 segundos); lo bueno era que la búsqueda en sí era súper rápida.
Por un lado lo mejoré usando __slots__ (para que cada objeto Nodo ocupe menos memoria, algo sólo relevante cuando uno tiene tantos y tantos objetos). Por otro lado, encontré y solucioné una ineficiencia importante: tenía un nodo casi al pedo en cada hoja del árbol. Con estas dos correcciones, el sistema pasó a ocupar 55 MB en memoria, y tardaba 4 o 5 segundos en levantar.
Hasta acá, todo bien.
Pero luego, Humitos se dió cuenta de que tanto su programa como el mío tenían algunos problemas en aquellas palabras que simultáneamente eran completas y parte de otras. Siguiendo con el ejemplo anterior, tenemos allí dos casos de estos: joyel es palabra completa, pero a su vez parte de joyelero; lo mismo con joyer y joyero (por otro lado, joye, por ejemplo, es sólo parte de otras palabras, no una palabra completa por si misma).
El problema era tan sutil que se mostraba en algunos casos y en otros no, dependiendo del orden de las letras (y esto era provocado por la forma en que armábamos la estructura palabra por palabra).
Estuve como tres horas en la oficina peleándome con esto, pero luego tuve que hacer otras cosas (trabajar, bah) y no lo pude solucionar. El código se iba complicando y complicando, y no le encontraba la vuelta.
Esa noche era el concert de uno de los jardines de Moni, así que tuve como media hora de auto hasta allá. En esa media hora el cerebro trabajó tranquilo, y me di cuenta de tres cosas....
Por un lado debía dejar de usar clases para el Nodo, una estructura de diccionarios debía de servir si encontraba la manera de marcar el fin de las palabras. Por otro lado, en lugar de ir armando la estructura palabra por palabra, seguramente sería más fácil a nivel de código el armarla teniendo todas las palabras y recorriéndolas por "columnas" de letras.
Esas eran optimizaciones, pero también se me ocurrió un cambio más fundamental. En los finales de las palabras, en muchos casos seguramente la estructura pierde forma de árbol frondoso y como que le quedan "ramas peladas". En estos casos, en lugar de almacenar secuencias de nodos, es mucho más eficiente guardar el resto de la palabra y listo.
Para verlo mejor, les redibujo el ejemplo anterior, pero bajo este concepto:
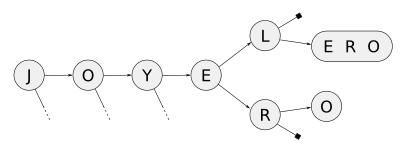
Como es una especie de Trie degenerado, excusándome bajo una incapacidad total a la hora de los nombres, y considerando que la versión anterior me tenía un poco frustrado, lo terminé llamando Fucked Trie.
Llegué al concert bastante antes que los padres, pasaron 40, o 45 minutos antes de que se ocupara el salón. Ese tiempo lo pasé codeando tirado en un rincón, e implementé el 95% de lo que sería la solución final. Le terminé de dar un par de retoques el lunes o el martes pasado, en Brasil, donde le corrí el profiler y optimicé un par de detalles.
El producto final tarda menos de un segundo en cargar, ocupa sólo 18 MB de memoria, y hace las busquedas en 60 micro segundos, centenares de veces más rápido que antes... ¡una preciosura! El código, junto con el diccionario de palabras, acá.

