Las siguientes son dos anécdotas sobre la utilización de Chat GPT.
¿Por qué Chat GPT? Porque es la IA que tengo instalada en el teléfono, y en ambos casos era piola poder resolverlo desde ahí.
¿Por qué les traigo estas anécdotas? Porque son casos de aplicación bien distintos, y un poco fuera de lo que siempre se resalta de las IAs (especialmente en el campo del desarrollo de software). Una es configuración de sistema operativo, y la otra es arreglar algo físico.

Configurando un Linux
La compu que venía usando Moni no daba más. La habíamos comprado bien al principio de la pandemia, una bastante tranquilita, y la vino usando desde ese momento todos los días, bastante, llevándola de un lado para el otro.
Decidimos comprar otra, y luego de algún análisis terminamos eligiendo una IdeaPad 15". La compramos vía Amazon, la recibimos una semanita después, todo joya. Ni bien recibirla, le instalé Kubuntu 24.04. Y aunque siempre es un detalle ver cómo entrar al BIOS, que botee del pendrive, y luego instalarlo más allá de lo que ya tiene de Windows y sus protecciones, anduvo todo de una.

Excepto un detalle: cuando bajabas la tapa, y la volvías a levantar, no andaba el teclado. Agarré el teléfono, más que nada porque justamente el teclado de la compu no arrancaba, abrí Chat GPT, y le planteé el problema.
En estos casos trato de ser lo más escueto y genérico posible, para no dar información por sentada que quizás limite la búsqueda o posibles investigaciones. Le dije: "Ubuntu en el ideapad funca ok, pero cuando cierra la tapa y la levanto, no anda el teclado (sí el pad del mouse)".
Me fué pidiendo algo de info al principio, para tratar de acotar qué teclado tenía justo esta Ideapad, cómo lo veía el kernel de Linux, si el driver tal o cual cosa, etc. Empezamos a probar de cambiar algún parámetro acá o allá, cambiar una config de booteo para la administración de energía, ver qué info tiraba en los logs al arrancar la máquina o luego al levantar la tapa.
Y acá apareció algo de usar esta tecnología que de otra manera es un embole: el análisis de logs y la búsqueda a partir de ellos. En este caso donde no me andaba el teclado, yo hubiese tenido que leer los logs, entender donde había info relevante, copiarla a otra compu, buscar, etc...
Acá lo que yo hacía era sacarle una foto a la pantalla.
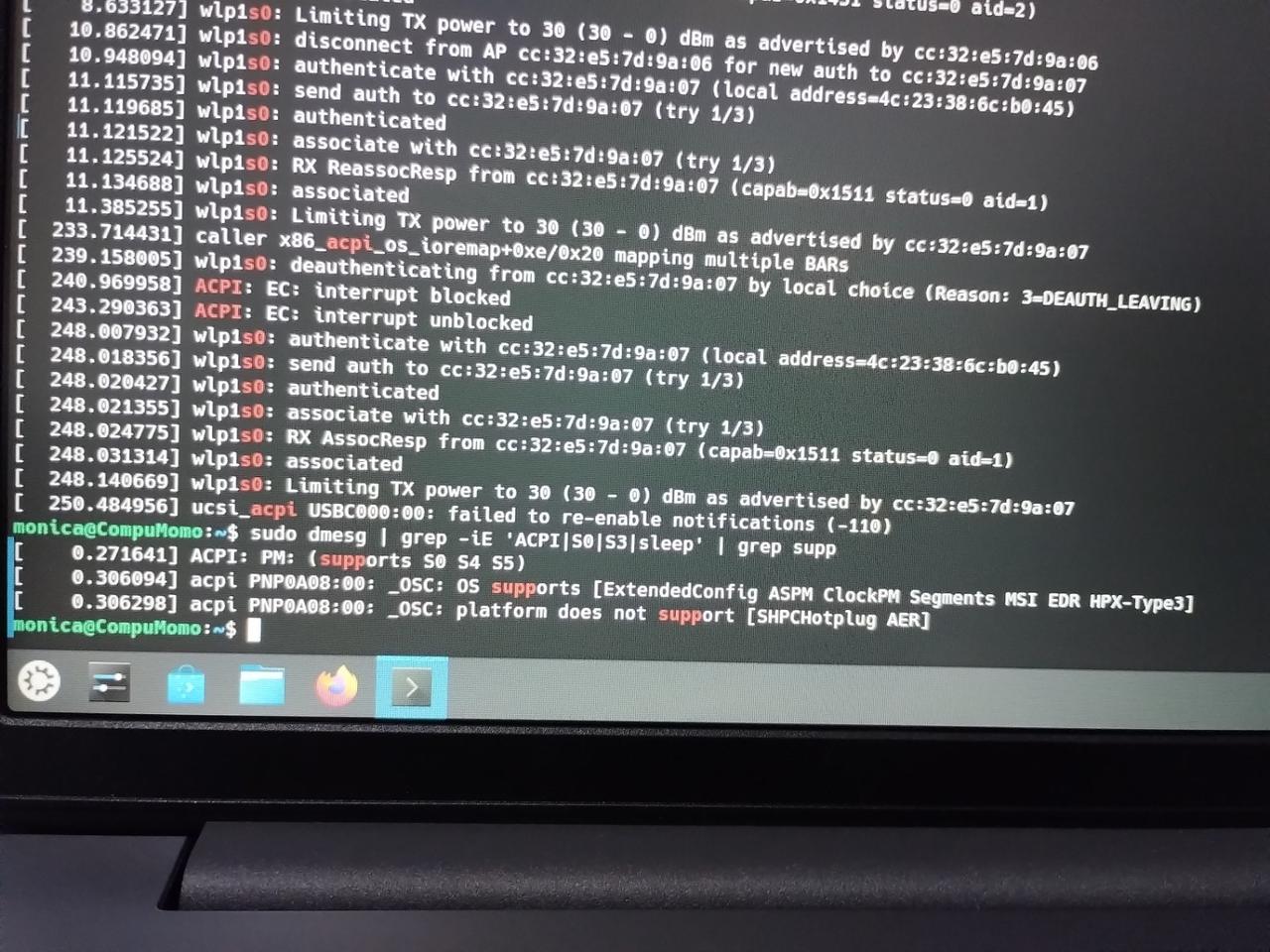
Sí, eso. Le sacaba una foto a la pantalla y se la pasaba a Chat GPT, que leía la foto (bueno, OCR y eso) y buscaba lo más relevante, y volvía con más info o cosas a probar. Por ejemplo, le pasé la siguiente foto y se dio cuenta que el modo "S3" de suspensión no estaba incluido en el log (dice ACPI: PM: (supports S0 S4 S5) en vez de algo como supports S0 S3 S4 S5), entonces con eso descartó una serie de pruebas.
Probamos un montón de cosas. Que si era lo que disparaba cerrar/abrir la tapa o el suspender en sí. Que el modo de suspensión. Que el driver, si agregado o dentro del kernel. Que qué pasaba en una consola virtual. Que si era del kernel, el desktop, libinput o X11.
Todas esas pruebas descartaban situaciones pero sumaban info. En un momento se puso a buscar situaciones reportadas similares, y encontró un caso con una máquina similar, con ubuntu similar, donde la solución reportada era:
sudo tee /etc/modprobe.d/amd_pmc.conf <<< 'options amd_pmc enable_stb=1'
Y pumba. Hice eso y el problema se solucionó.
¿Podría haber llegado yo a esta misma conclusión? Quizás, luego de horas de búsquedas, pruebas, y aprender montonazo de cosas bajo nivel que tampoco tengo ganas de meterme. ¿Alguien con más experiencia podría haber llegado a lo mismo en menos tiempo? Ponele que sí, ¿pero quién?
Entonces, quería resaltar esta utilización de la IA como "ayudante de investigación", donde te va mostrando/enseñando sobre los subsistemas del sistema operativo, pidiendo pruebas, guiándote a una solución.
La verdad, fue una ayuda genial. Acá les dejo la conversación completa.
Arreglando una ventana
Cuando refaccionamos la casa actual, para la parte nueva decidimos poner ventanas de doble vidrio, ya que aunque son más caras al principio, luego es negocio en lo que se ahorra de calefacción / refrigeración, y encima aisla mejor los ruidos externos.
Para los baños decidimos poner unas ventanas de tamaño medio (no eran ventanales, tampoco ventiletes) pero que tienen la particularidad de que son oscilobatientes: se pueden abrir de dos maneras distintas: como una ventana normal, o con un pequeño ángulo en vertical, como ventilación.

Hace un par de semanas encontré que una de estas ventanas funcionaba mal. No terminaba de cerrar, y por eso mismo se trababa el mecanismo de la manija, que tiene las tres posiciones que se ven en la imagen. La ventana se podía abrir del todo en "la vertical" (hasta ese ángulo que permite) o apenas apoyarla contra el marco. Pero no funcionaba correctamente.
Contacté al soporte de postventa de la gente que me vendió e instaló todo esto en la obra, y me pasaron presupuesto. Un PDF, que abrí y miré así nomás, decía 120. Pensé: medio careli, 120 lucas sólo por ajustar la ventana (sin repuestos, digamos), pero bueno, todo está caro hoy en día. Tipo a la semana me decidí y le dije al de soporte que avancemos. Me pasó el CBU para que mande el total, antes de planear una fecha. Qué carajo. Me fijo en el presupuesto, para ver que decía del pago adelantado, lo leo bien y ahí me doy cuenta que no decía 120 mil pesos, decía 120 dólares. Me pareció un despropósito.
Entonces me tiré a ver si la podía arreglar yo. De última los llamaba, pero como último recurso.
Como en el caso anterior, le pregunté a Chat GPT. Me dijo de donde se podía ajustar, porque la ventana tiene unos buloncitos excéntricos que se mueven con una llave allen y permite llevar a la ventana a que cierre perfecto. Pero no pude. Y a los diez minutos de jugar con los ajustes, se me cae la llave allen entre la ventana y el mosquitero, y no podía meter el brazo para sacarla.

Eso cristalizó un poco las cosas, y decidí sacar la ventana, y terminar de entender si el mecanismo no andaba porque la ventana no cerraba, o la ventana no cerraba porque el mecanismo no andaba. Y de última sacaba la llave allen, volvía a poner la ventana, y llamaba a soporte.
Una vez sacada la ventana el misterio aumentó: el mecanismo seguía sin moverse bien, pero ahora ya estaba seguro que no estaba "mal-encajando" en la estructura del marco. Le conté a Chat GPT lo que pasaba, y le mandé un par de fotos.

Me fue contando cosas que veia, y describiendo cómo trabajaban los mecanismos, todo aprendizaje para mí. En un momento dice "No veo ninguna pieza rota a simple vista, pero sí es muy posible que alguno de los carros internos de la cremona se haya salido de sincronización o que un seguro anti-falsa maniobra haya quedado enganchado.".
Eso me hizo sospechar de algo que veía, un pitoncito mínimo, que se movía raro. Fui al otro baño y comprobé que ese cosito se movía de forma muy distinta. Entonces le mandé otra foto más con ese comentario:

Y me contestó "Ese pestillo negro que se ve en la foto es, efectivamente, el seguro anti-falsa maniobra", y un par de recomendaciones, principalmente que le ponga WD-40 y trate de hacerle fuerza para destrabarlo. Hice eso, y el pitoncito se hundió, ¡y la ventana empezó a trabajar bien! No fue todo éxito, sin embargo, porque el pitoncito no volvió a salir :/
La IA me dice entonces que no había demasiado problema en que quede hundido, "De hecho, muchos fabricantes venden herrajes sin ese seguro, o hay gente que lo inmoviliza cuando da problemas. El único efecto es que desaparece la protección contra girar la manija cuando la hoja está abierta. No afecta el cierre ni la estanqueidad.".
Me dispuse entonces a volver a poner la ventana. La puse en su lugar, y efectivamente cerró todo bien. Es más, no logré encontrar qué "movimiento mal" puedo hacer ahora que el pitoncito está hundido.
Lo que quiero al contarles esta segunda experiencia es resaltar el dominio de aplicación. Porque al final la ayuda fue un poco como en el primer caso donde fue guiando mis acciones, enseñándome sobre el mecanismo, pidiéndome que pruebe cosas. Pero en este caso sobre una reparación "física", una ventana de mi casa. Nada que ver para lo que uso la IA en el día a día...