¿Qué es?
La CDPedia es la Wikipedia Offline. O sea, la Wikipedia, lo más fiel posible a su formato y contenido original, pero armada (construida, compactada) de una manera que no se necesita nada de Internet para acceder a toda la info de la misma.
Se llama CDPedia porque la idea original era meterla en un CD. Hoy por hoy generamos cuatro imágenes en cada liberación de CDPedia: un CD, un DVD, y dos archivos comprimidos (uno mediano y otro grande) que se pueden poner en un pendrive o en cualquier disco rígido.
La CDPedia es multiplataforma: el mismo CD, DVD o archivo comprimido se puede usar en Linux, Windows, o Mac, sin necesitar nada instalado previamente por fuera de lo que cada sistema trae normalmente.
¿Cómo se usa? ¿Cómo se ve?
Para usarla, lo primero es descargarla. Pueden acceder a la página del proyecto y ahí encontrarán info acerca de las cuatro versiones que tenemos actualmente, con el detalle de cuantas páginas y cuantas imágenes tiene cada una. Para bajarlo, necesitan un cliente de Torrent; para Linux a mí me gusta mucho el Deluge, que también puede usarse en Windows y Mac; otro cliente recomendado para las tres plataformas es qBittorrent.
Si descargan la versión CD o DVD, lo primero que tienen que hacer es grabarlo a un disco virgen, para lo cual necesitan una grabadora y un software para grabar. Si usan Windows y no tienen ninguno instalado, les recomiendo InfraRecorder que es software libre y muy fácil de usar. Pongan el disco generado en el equipo y ejecuten la CDPedia.
Si descargan las versión tarball, directamente descompriman los archivos en el disco rígido. Entren a la carpeta descomprimida y ejecuten la CDPedia.
¿Cómo se ejecuta la CDPedia? Bueno, depende de cada sistema. En Windows con hacer doble click en cdpedia.exe, alcanza. En Linux o Mac, si tienen bien configurado el navegador de archivos, debería funcionar haciendo doble click en cdpedia.py, pero siempre pueden recurrir a abrir una terminal, ir hasta el directorio en cuestión, y hacer ./cdpedia.py.
En cualquier caso al ejecutar ese archivo se va a levantar el Server de CDPedia, y al mismo tiempo se abrirá un navegador apuntando a ese Server local. Luego, es sólo usarla, ya que se explora y utiliza de la misma manera que la Wikipedia Online (con la excepción obvia que la CDPedia es de lectura solamente: no permite editar el contenido como sí lo hace la Wikipedia).
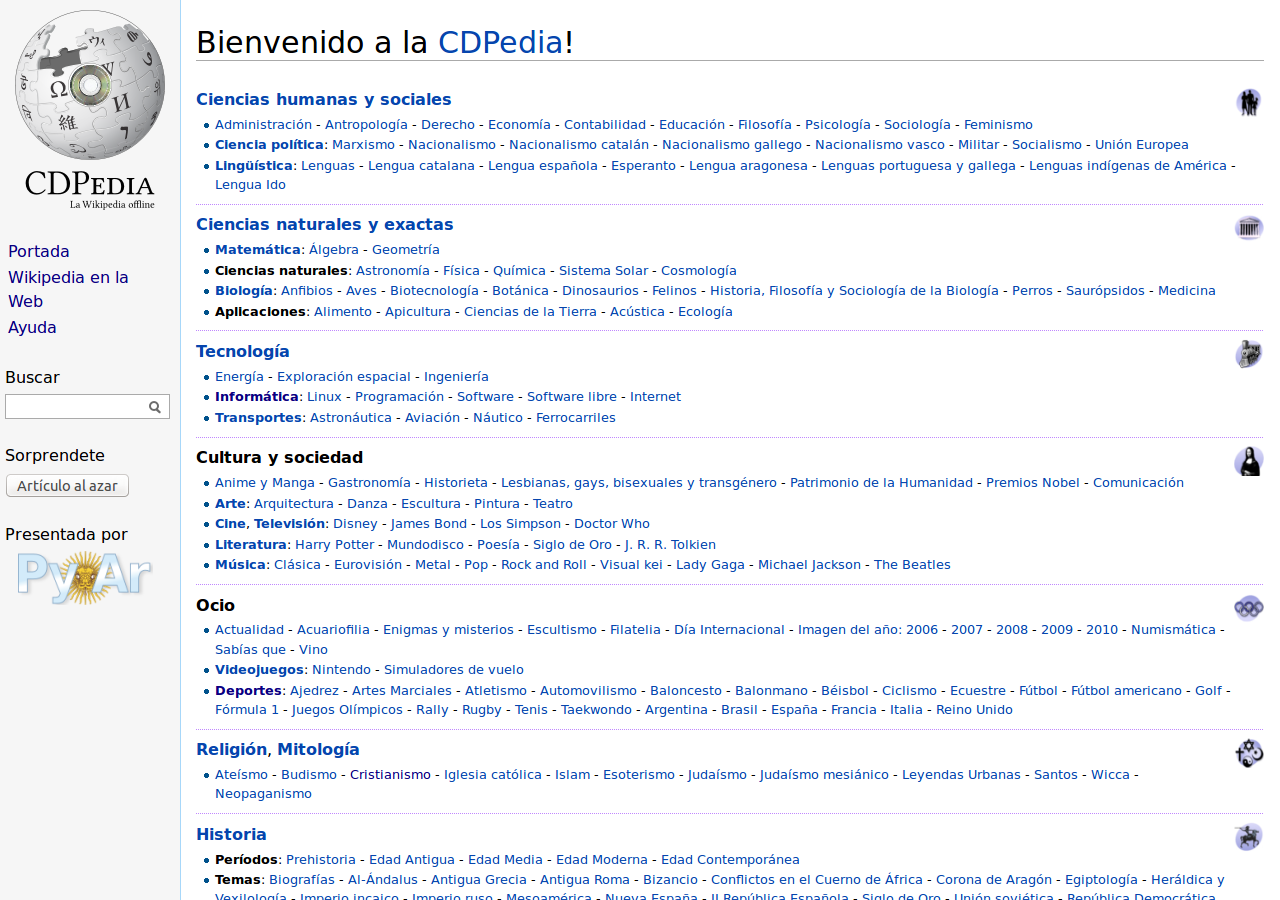
(a este y otros screenshots, hagan click para verlos más grandes)
Una decisión estratégica de la CDPedia es tomar el HTML generado por los servers de Wikipedia y usarlos casi directamente (les recortamos unos headers, optimizamos algunas cositas). Exploramos en algún momento tomar la info de la base de datos directamente, pero no logramos generar una página web igual a la de Wikipedia online.
Y eso es una fortaleza de la CDPedia: por la manera en que armamos las páginas, la forma de ver y usar las páginas, de explorar y acceder a la información, es igual a la Wikipedia online, de manera que el usuario no tiene un costo cognitivo en pasar de la versión online a offline. Es más, también se puede considerar a la CDPedia como el paso previo de consumo de contenido a la Wikipedia: una persona se puede acostumbrar a explorar las páginas, leer, cruzar y criticar la información, etc, y recién cuando tiene todo armado va a la Wikipedia Online y al resto de Internet para completar su investigación.
Más allá de la página a nivel contenido, lo que sí modificamos mucho es la barra de la izquierda. No tiene la original de Wikipedia, porque no tiene sentido al ser todo offline, así que reemplazamos los botones y enlaces por otros: hay un botón para ver una página al azar, un campo de texto de búsqueda, el logo de CDPedia, el logo de PyAr, enlace a una página de ayuda, etc...
Algo que también modificamos bastante es como señalizamos los enlaces en la página misma, en el contenido de Wikipedia. Hay principalmente tres tipos, distinguibles en cómo decoramos el texto convertido en enlace:
Azul: un link normal, apunta a otra página de Wikipedia que se incluyó dentro de CDPedia.
Rojo, subrayado con guiones: un enlace a otra página de Wikipedia pero que no fue incluida en CDPedia por razones de espacio.
Azul, subrayado con guiones: un link que los sacaría de CDPedia, ya que apunta a recursos online (útiles solamente si tenés Internet, claramente).
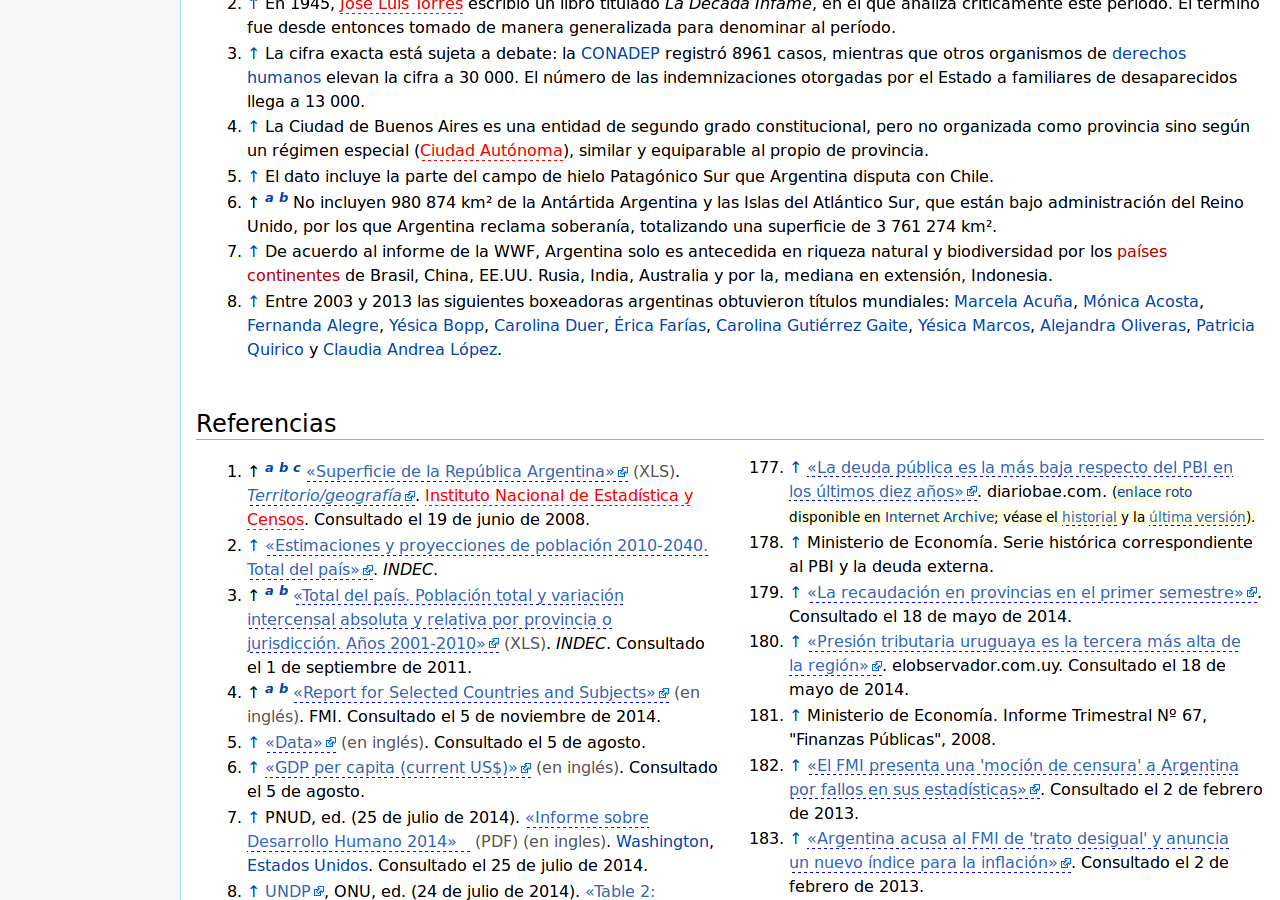
Otra sección que modificamos es el pie de cada página: ponemos un enlace a la misma página pero online, en Wikipedia misma, por si el usuario necesita la información actualizada. También aquí incluimos el contenido original, ponemos algún disclaimer extra, mencionamos que CDPedia es un proyecto de Python Argentina (y apuntamos al tutorial de Python que está incluido en la CDPedia).
Cabe mencionar que la CDPedia funciona también en Modo Servidor. De esta manera, se puede instalar la CDPedia en el servidor de una escuela, y que todas las computadoras del establecimiento puedan usar la información desde allí. Así logramos el efecto deseado de que los chicos puedan tener acceso al contenido de Wikipedia sin realmente tener Internet, pero sin la complicación o el incordio de tener que instalar CDPedia en cada una de las computadoras. Acá hay más instrucciones para configurarla de este modo.
¿Qué contenido tiene?
El contenido de la CDPedia está fuertemente determinado por dos características intrínsecas del proyecto: la CDPedia es estática y fácilmente distribuible en un disco o pendrive.
Digo que la CDPedia es estática porque una vez armada, no se actualiza. Es por eso una especie de "fotografía de un momento de Wikipedia" que, por definición, siempre va a estar desactualizada.
Cuando se comienza a generar una nueva versión de la CDPedia, se baja la versión más actualizada de todo el contenido de Wikipedia y se empieza a procesar. Este procesamiento puede llevar varias semanas, incluso unos meses. Entonces, cuando se libera una nueva versión de CDPedia, no incluye todos los cambios que se generaron en Wikipedia misma desde que se empezó a procesar.
Es por esto que se trata de liberar una versión de CDPedia al menos una vez por año, para que contenga la información lo más actualizada posible.
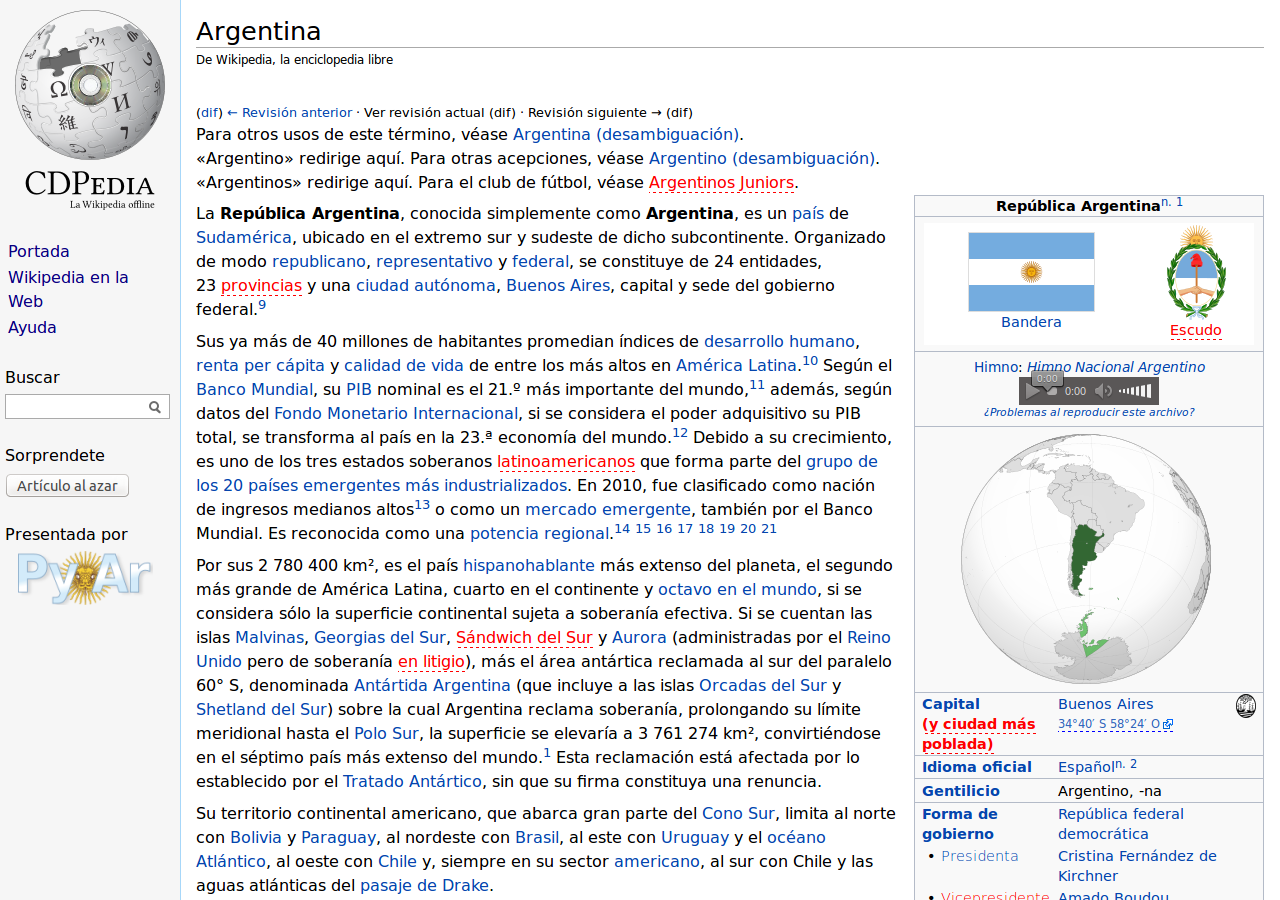
También digo que la CDPedia se puede distribuir fácilmente: sólo hace falta quemar un CD o DVD, o incluso pasarse los archivos mediante un pendrive. En casi todas las versiones (menos la más grande), por una cuestión de formato, no entra todo el contenido de la Wikipedia. Por ejemplo, para la versión 0.8.3, tenemos lo siguiente:
CD (693 MB): 54 mil páginas y 5% de las imágenes
Tarball medio (3.6 GB): 400 mil páginas y 20% de las imágenes
DVD (4.3 GB): Todas las páginas y 8% de las imágenes
Tarball grande (8.7 GB): Todas las páginas y todas las imágenes
Entonces, a menos que estemos armando el tarball grande, es evidente que tenemos que decidir cuáles páginas e imágenes van a entrar, y cuáles van a quedar afuera.
Esa decisión se toma ordenando todas las páginas por un determinado puntaje (que explico abajo), y se eligen las primeras N páginas (para el ejemplo anterior, las primeras 54 mil para el CD, las primeras 400 mil para el tarball medio, etc). Esas páginas tienen a su vez imágenes, que naturalmente también quedan ordenadas por el puntaje de las páginas: se toma un primer porcentaje de imágenes que se incluyen al 100%, otro porcentaje de imágenes que se escalan al 75%, otro porcentaje de imágenes que se escalan al 50%, y el resto no se incluye.
Como vieron, un tema clave en la selección es darle un puntaje a las páginas. Este puntaje está formado (hoy por hoy) en base a dos factores: levemente por el largo de la página (una página larga tiene más puntaje que una corta), y fuertemente por lo que llamamos "peishranc", que es la cantidad de otras páginas que enlazan a la que estamos evaluando. Entonces, si a una página se la menciona en otras mil páginas es mucho más importante que una página que casi no se la menciona en el resto de la Wikipedia.
Otro gran detalle en lo que es "contenido" es qué hacemos para mitigar el problema de la vandalización. O sea, cómo evitamos en lo posible incluir páginas que fueron vandalizadas. Cuando comienza el proceso de generar una nueva versión de la CDPedia, como les comentaba antes, bajamos todas las páginas de Wikipedia, ¡pero no siempre bajamos la última versión! Lo que hacemos es revisar cuándo fue modificada y por quién: si fue modificada por un usuario normal, perfecto; pero si fue modificada por un usuario anónimo (como sucede en la mayoría de las vandalizaciones) nos fijamos cuando fue modificada: si fue hace más de varios días, la incluimos (asumimos que la gente de Wikipedia ya tuvo tiempo de verificar el cambio), pero si es muy reciente evitamos la última versión de la página, y agarramos la versión anterior (y aplicamos nuevamente todos estos mismos controles).
¿Cómo surgió el proyecto?
Cuenta la leyenda que el proyecto arrancó en el sprint posterior al primer PyDay de Santa Fé, en Junio del 2006, con la idea base de poder distribuir la Wikipedia a aquellos lugares que no tenían o tienen acceso a Internet (en particular teníamos en mente a escuelas de frontera o de ciudades chicas, bibliotecas de barrio, centros culturales de pueblos pequeños, etc.).
El proyecto continuó, y aunque no siempre le pudimos dedicar tiempo, tampoco nos alejamos nunca demasiado. Las mejoras en el proyecto fueron muy por ráfagas. Quiero destacar que fuimos muchos los que colaboramos con el proyecto, a lo largo de los años, ¡casi 30 personas!
Se trabajó mucho en este proyecto durante los PyCamps (los dos en Los Cocos, el de Verónica, y el de La Falda), donde muchas personas le dedicaron un buen tiempo, y también se realizó bastante durante otras reuniones, especialmente durante el 2010 y 2011.

A modo de ejemplo, dos sprints: uno fue en un incipiente hacklab, donde se experimentó mucho sobre el índice para las búsquedas, y también durante la fundación de Wikimedia Argentina, donde se presentó por primera vez el proyecto y se realizó un gran avance en la primera parte del procesamiento de datos.
En años más cercanos yo traté de involucrar colaboradores en algunos sprints efímeros que armé, con poca suerte. Lamentablemente en el último tiempo fui principalmente sólo yo el que empujó el proyecto (lo cual es una autocrítica, más que un autoreconocimiento).
Una gran característica de la CDPedia, indiscutiblemente el proyecto más grande y más largo de Python Argentina, es que siempre se mantuvo orientado a los mismos objetivos: tener una Wikipedia offline con fines sociales (distribuir en escuelas sin conexión a Internet, que el conocimiento sea libre, etcétera), que sea divertido de hacer (es decir, hacerlo en Python), y mantenerlo libre (no sólo el producto final, que recomendamos copiarlo y repartirlo, sino el código en sí).
¿Se puede espiar abajo del capot?
¿Cómo se arma la CDPedia? ¿Cómo se logra cumplir todo lo que expliqué arriba?
Es bastante sencillo: hay que bajar el código con git desde la página del proyecto en github, y luego correr un script que hace todo solo: el cdpetron.
Este script tiene bastantes opciones (especialmente para no repetir partes del proceso: que no vuelva a listar todas las páginas, que no vuelva a bajarlas, que no limpie todo antes de comenzar, etc), pero lo básico es que se le especifica de dónde tomar el código, donde bajar y dejar páginas e imágenes, y en qué idioma trabajar.
Incluso hay una manera de correrlo en modo test, para que haga solo una parte del trabajo y poder arrancar pronto a probar cosas, ideal para mezclarlo con la opción de generar una sola de las versiones:
$ utilities/cdpetron.py --test-mode --image-type=beta . /tmp/dumpcdpedia es
El comando anterior tarda relativamente poco (menos de cinco minutos en una máquina normal y con buena conexión a Internet) y nos deja todo el proceso realizado, pero con pocas páginas.
Ver lo que obtuvimos es sencillo, porque más allá de generarnos el tarball o el .iso correspondiente, podemos probar la CDPedia directamente del directorio donde realizamos el proceso, haciendo:
./cdpedia.py
...lo cual levantará el server y nos abrirá el browser, tal cual si lo hiciéramos de la versión final (pero con la ventaja que podemos pararlo, cambiar el código para probar el algo, levantarlo de nuevo, ver los resultados, etc.)
¿Y cómo es el proceso que realiza? Bueno, la estructura interna (y el proceso para obtenerla) de la CDPedia está muy influida por la necesidad de optimizar al máximo la compresión y el acceso a la información, de manera de poder meter en cada formato (CD, etc...) la mayor cantidad posible de artículos e imágenes.
Podemos delinear el proceso que se realiza en en el siguiente gráfico:
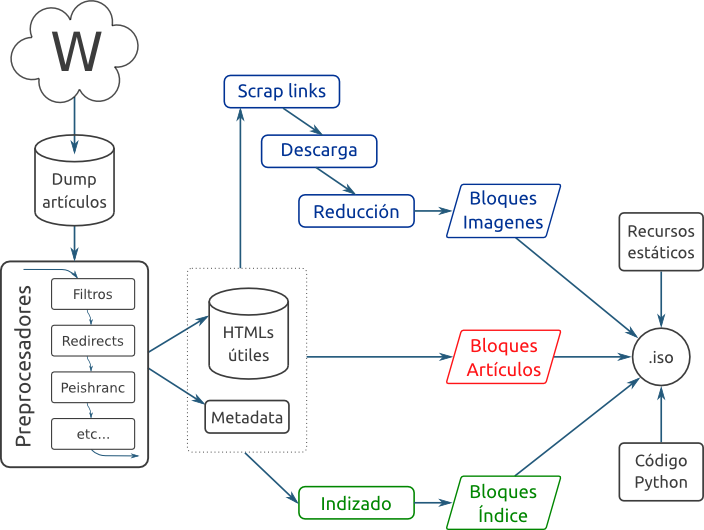
El primer paso es bajar de la Wikipedia misma todas las páginas (lo que realmente tiene dos sub-pasos, un listado general de todas las páginas que nos interesan, y luego efectivamente bajarlas). Esas páginas son pasadas por diferentes preprocesadores que hacen distintos trabajos. Algunas las filtran y eliminan páginas que no queremos, otras les asignan puntajes, otras las modifican mejorándolas para nuestro objetivo, otras extraen información que va a ser útil luego.
Al final de ese preprocesamiento tenemos dos grandes resultados intermedios: los HTMLs "útiles", más un montón de metadata. Aquí se abren tres grandes ramas de trabajo.
La primera es el manejo de las imágenes. Se buscan los enlaces en las páginas, se descargan todas las imágenes necesarias (que pueden no ser todas, dependiendo de la versión generada), se reducen las que corresponden (algunas se incluyen al 75% o 50% de su tamaño) y finalmente se arman los llamados "bloques de imágenes".
Por otro lado, con los resultados intermedios se generan los "bloques de artículos".
Y finalmente, se procesan todos los títulos de las páginas más algo de metadata y se hace pasar por un complejo algoritmo matemático que nos pre-arma la información para generar los "bloques del índice".
A esta altura tengo que explicar qué son estos "bloques" de imágenes, artículos o índice. Es una estructura no demasiado compleja pero muy bien pensada para el objetivo de la CDPedia que es funcionar sin usar demasiada memoria y poco espacio en disco. Básicamente tenemos bloques de información comprimidos de forma independiente: es un equilibrio entre comprimir todo por separado, o comprimir todo junto; logramos mejor ratio de compresión que comprimiendo la info por separada, y no tenemos que descomprimir algo demasiado grande al no estar todo junto. Para decidir qué bloque consultar hay un hasheo y selección, y luego dentro de cada bloque hay un índice binario de contenidos, pero no mucho más.
Finalmente, con estos bloques, más algunos recursos estáticos (imágenes, CSSs, algo de JSs, el tutorial de Python comprimido, etc.), más el código de Python propiamente dicho para servir la CDPedia, se arman los tarballs o .ISOs.
¿En qué situación está el proyecto actualmente?
El proyecto avanza, pero lento.
Hay varios bugs abiertos, incluso algunos que son críticos porque se muestran un par de cosas feas luego de un cambio de formato de las páginas de Wikipedia, pero yo personalmente no estoy haciendo foco ahí, sino que estoy empujando un par de cambios más grandes.
Uno de ellos es lograr la internacionalización de la CDPedia. Cuando esté terminado, se van a poder crear CDPedias no sólo a partir de la Wikipedia en español, sino también de la Wikipedia en otros idiomas: portugués, aymara, guaraní, alemán, ruso, etc...
El otro cambio es más bien la construcción de una infraestructura en particular. Mi idea es tener una generación continuas de CDPedias, que se arme la CDPedia en español, y automáticamente luego se arme la de otro idioma, y otro, y otro, y otro, y luego de varios meses, vuelva a arrancar con la de español.

Pero, como decía, hay mil cosas para hacer.
Unos chicos en un PyCamp hicieron una app para Android que, luego de copiar los datos a mano, correría la CDPedia en cualquier teléfono o tablet (yo traté recientemente de usarlo y tuve unos problemas y no lo pude hacer andar del todo).
Otro detalle que necesita trabajo es que el código en sí está bastante feo... mezcla inglés y castellano, no cumple PEP 8 ni PEP 257, tiene poco y nada de pruebas de unidad, etc.
Si tienen ganas de participar de cualquier manera, lo principal es que se pongan en contacto con el grupo en general, a través de la lista de correo o del foro asociado (son espejo uno del otro, usen el que sientan más cómodo). Lo mismo si desean hacer cualquier consulta, o ponerse en contacto para cualquier inquietud.
CDPedia necesita amor. Programadores con ganas de trabajar y aprender, tiempo de programador para continuar llevando este proyecto tan interesante y valioso por buen camino.





