Hace rato que tenía ganas de aprender un poco sobre el arroz.
Me llamaba la atención que esté ese "arroz para sushi" que en su preparación se le pone vinagre y sale muy "pegajoso" para armar las distintas piezas. O que esté la dicotomía entre "hacerlo en mucha agua y colarlo" y "hacerlo en la cantidad justa de agua". O que para la paella recomienden "ni tocarlo" y en el risotto le hagan bailar la tarantela.
Empecé a juntar algo de info, entonces, de lo cual resumo un poco a continuación y le doy algo de orden, haciendo foco en los detalles que me interesaron. Obviamente no es un "tratado sobre el arroz", nada más lejos de eso, y toda la data que tiro acá se puede encontrar más o menos rápido en Internet; si quieren profundizar arranquen por Wikipedia, el INTA, y Alimentos Argentinos.

Lo primero que quiero resaltar, para tirar abajo todas esas recomendaciones o recetas genéricas que te dicen "al arroz hay que hacerlo de tal manera o hacerle tal cosa", es que no podemos hablar de "el arroz".
Hay cerca de diez mil variedades de arroz, con un buen rango de distintas propiedades, entonces siempre hay que ser un poco más específicos, y hay que tener especial cuidado si estamos viendo recetas o recomendaciones de otros países ya que quizás no usen el mismo tipo de arroz que nosotros. Todas estas variedades son de la misma especie Oryza sativa (que me causa gracia su nombre porque la "oriza" es una especie de plato con filo que se usa en un libro de Stephen King como arma para decapitar enemigos, al tirarla como un disco), y tiene dos subespecies: la índica, que suele cultivarse en los trópicos, y la japónica, que también crece en climas templados y se caracteriza por su alto contenido en almidón (ya vamos a ver donde esto es importante).
Además, también depende de procesos que se le hagan al arroz luego de cosechado. El más común, que se le hace a la mayoría de arroces, es que se "pulen" para sacarles de la cubierta que los protege (que se convierte en salvado), lo que elimina así aceites y enzimas del arroz. Pero también hay otros procesos, algunos cuento abajo.

Se produce mucho arroz. Alrededor de 750 millones de toneladas anuales, lo cual, obviamente, no nos dice nada porque no llegamos a "entender" un número tan grande. Las proporciones y comparaciones ayudan: el 90% de la producción y del consumo se concentra en el continente asiático.
En otras palabras, el 10% se produce y consume afuera de Asia. América es el segundo continente (aproximadamente un 6% del total), de lo que le corresponde un tercio a Brasil, el principal productor.
Argentina, puntualmente, no se destaca: sólo un 3.5% del continente. Concentra su producción en Corrientes (50%), Entre Ríos (32%), Santa Fe (13%) y el resto principalmente distribuido en Chaco y Formosa.
Algunos detalles del arroz a nivel nutricional:
tiene más lisina que el trigo/maíz/sorgo; la lisina es uno de los nueve aminoácidos esenciales para los seres humanos, y debemos incorporarlo de alguna manera
ojo cuando está limpio (sin salvado): tiene menos fibra que otros cereales
proporciona mayor contenido calórico y más proteínas por hectárea que el trigo y el maíz (lo que es importante a la hora de alimentar poblaciones)
¡no tiene gluten! por lo tanto es apto para consumo por personas celíacas o con otras sensibilidades al gluten, pero no puede usarse para hacer panificados

Decía que hay muchos tipos de arroz. La principal categorización es por la forma, o más bien por la relación entre su largo y su grosor (no podemos dejar de mencionar a Les Luthiers... "Mi nombre es Oblongo, que en dialecto Swahili quiere decir más largo que ancho").
Tenemos varios tipos:
grano corto: es casi esférico, ideal para sushi porque los granos quedan unidos incluso a temperatura ambiente.
grano medio: su longitud es de entre dos y tres veces su grosor; es el que más se consume en Argentina en particular, sudamérica y centroamérica en general, y es el tipo de arroz que se usa en el risotto o la paella (el arroz bomba pertenece a esta categoría).
grano largo: es entre cuatro y cinco veces más largo que grueso, no se ve mucho por acá; tiene mucha amilosa (almidón), por lo que necesita mucha agua en la cocción.
silvestre: es de casi 2 cm de largo
A algunos tipos de arroz se les dice glutinosos, para indicar que son pegajosos después de cocerse (¡no que tienen gluten!), efecto que viene dado por el tipo de almidón que contienen. También hay los aromáticos, característica de algunos tipos de arroces que desprenden aromas (a flores, frutos secos, etc.) luego de ser cocidos.
También podemos separar el arroz en común o integral, aunque esto es sólo una cuestión de proceso. Al integral sólo se le quita la cáscara exterior (o gluma), que no es comestible. Conserva el germen íntegro con la capa de salvado que lo envuelve, lo que le confiere un color moreno claro.
Si entramos en el detalle de la estructura del grano de arroz, veremos que es similar al de otros cereales, especialmente a la cebada y avena que también tienen una cáscara externa. El grano está constituido fundamentalmente por cuatro partes:
una cáscara externa que envuelve el grano
el salvado, constituido por diferentes capas que se encuentran por debajo de la cáscara
el germen, que es el embrión de la semilla (la parte reproductiva que germina para crecer y dar lugar a una nueva planta)
el endospermo (la parte más importante del grano en peso y tamaño) que contiene nutrientes de reserva que son utilizados durante la germinación (principalmente almidón).
Ya mencionamos varias veces el almidón. ¿Qué es? Es una macromolécula, compuesto por dos tipos de glucosas, la amilosa y la amilopectina, en distintas proporciones (cuanto de una y de otra varía según el vegetal). Es la forma en que la mayoría de los vegetales reservan energía, y notablemente es el carbohidrato más consumido por humanos.
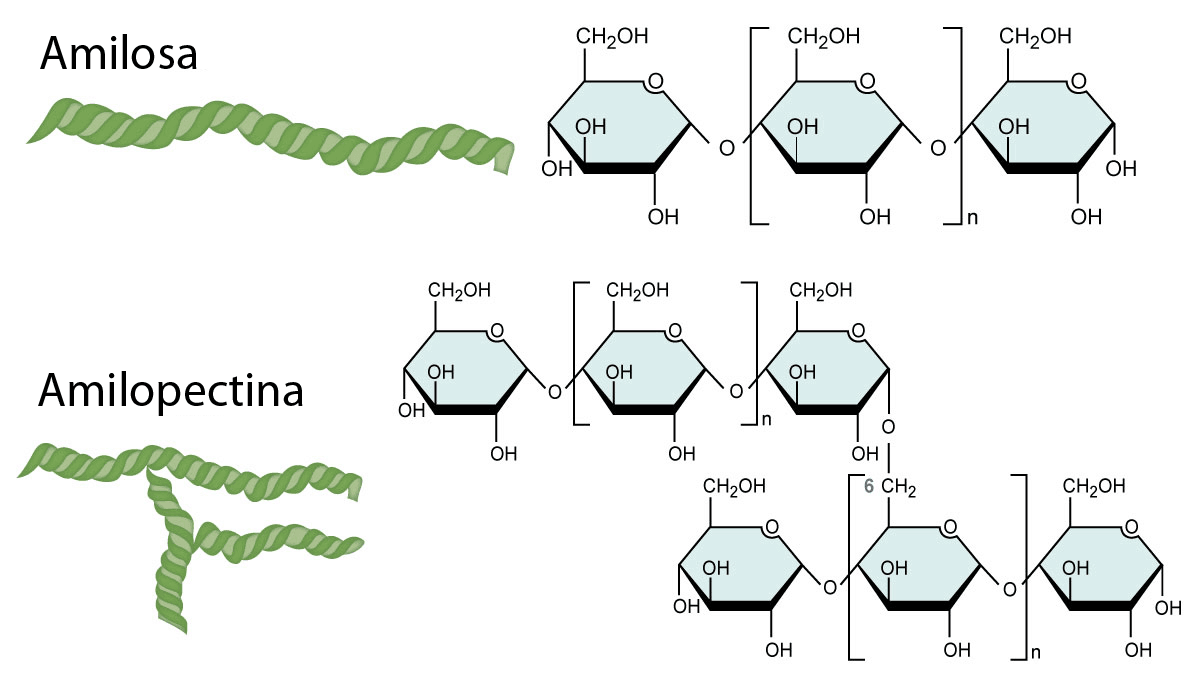
El arroz no es excepción y también contiene almidón. Nos afecta en dos situaciones, puntualmente.
El primero es el nutricional: aporta muchas calorías y no deja de ser un tipo de carbohidrato que convertimos en azúcar (lo cual es un riesgo para aquelles que sufren de diabetes). Habiendo dicho eso, existe algo que se llama almidón retrógado, que se consigue enfriando el arroz luego de cocinarlo, y que evita que el almidón sea digerido por el cuerpo, sino que pasa directamente y es aprovechado por los microbios intestinales. Así que ya saben, ¡nada como una buena ensalada fría de arroz!.
El otro detalle con respecto al almidón es que cuanta más amilosa contiene un grano de arroz, más temperatura, agua y tiempo requiere para su cocción, y más pegajoso quedará luego. Al lavar o enjuagar el arroz, sacamos una capa importante de almidón y de esta manera terminamos consiguiendo arroz suelto y seco luego de cocinarlo. Si decidimos conservar el almidón al final quedará cremoso y pegajoso. Entonces, si queremos arroz para una ensalada (como recomiendo arriba), mejor lavarlo, y si queremos hacer un risotto, mejor no.
Hay otro factor que afecta esta dinámica: revolver el arroz cuando se está cocinando. Si estamos buscando que la preparación no salga pastosa debemos evitar revolver mucho, para que el arroz no largue el almidón, lo cual sí queremos cuando hacemos un risotto (y por eso se lo mueve tanto).
Y antes de dejar de hablar sobre formas de cocinar el arroz, un detalle sobre lo cual estaba intrigado: el agregarle vinagre al arroz del sushi. Parece ser que esto se hace para evitar el crecimiento bacteriano (el vinagre es un bactericida natural, como la canela que se usan en algunas preparaciones de la India), ya que el arroz crudo suele llevar esporas en estado de hibernación como la bacillus cereus, que produce toxinas que afectan al sistema gastrointestinal. Estas esporas sobreviven las altas temperaturas de cocción, por eso el arroz debe servirse inmediatamente tras su cocinado o conservarlo refrigerado, lo cual es fácil hoy en día pero muchas recetas o costumbres provienen de épocas donde mantener en frío no era sencillo o directamente imposible.

Les había prometido unas palabras sobre procesos que se le hacen al arroz. De quitarle la cáscara exterior (y convertirlo de integral a pulido ya hablé antes). Vamos con algunos otros.
El parboilizado (o vaporizado) es el proceso donde se somete el arroz con cáscara a un remojo de 60 ℃ y luego a una fuerte presión de vapor. De esta manera se elimina una buena parte del almidón pero se conservan vitaminas y sales minerales (se trasladan de la fibra al grano) que los arroces tradicionales pierden durante su pulido. Es por esto que el arroz vaporizado tiene un 80% del valor nutricional del arroz integral. Luego del proceso el arroz queda más duro y brillante que otros arroces (porque el almidón se gelatiniza), lo que lleva a requerir más tiempo de cocción, quedando luego más firme y menos pegajoso.
El precocido es, obviamente, cocinar el arroz antes de presentarlo para su venta. El proceso es muy genérico, y se usa como medio para otros fines. Se destacan el lograr un "arroz de cocción rápida" (como característica de venta), precocer el arroz parboilizado (para compensar que ese proceso aumenta el tiempo de cocción necesaria), y el precocido y posterior deshidratado del arroz, para preparar comidas pre-hechas (como esas que vienen en un sobrecito para hidratar y calentar y te sale el guiso listo). Ojo, no confundir este proceso de deshidratación recién mencionado con el proceso de secado que se le hacen a todos los arroces luego de cosechados para que los granos no se deterioren mientras están almacenados.

Bueno, se hizo largo pero espero que les haya gustado. Yo, por lo pronto, aprendí un montón, así que objetivo cumplido :)
Lo que me quedó pendiente es hacer una investigación de mercado... ¿qué tenemos a "nuestro alcance" a la hora de comprar arroz? ¡Comenten si saben!